Amazon Launches Serverless Query Service – Amazon Athena
Amazon Web Services (AWS) has announced a lot of new AWS cloud services. One of the main services among them is ‘Amazon Athena’. It has been verified technically, as a data analysis service while comparing it with similar cloud services.
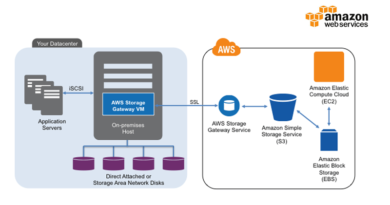
Athena can analyze data in large volumes and analyzing various types of data files fast, simple, and cheaply. It can withstand one terabyte or more of data. And since data manipulation can be performed with basic SQL command, data analysis can be performed as if operating as a database.
Amazon Athena uses Apache Hive used in big data analysis and creates tables and analyzes data with SQL commands. The Hive table creation SQL command has some quirks, but specialized knowledge is unnecessary because one can generate a basic table creation SQL command statement from a Web browser using the AWS management console. Then, by setting the storage location of S3 cloud storage familiar with AWS and access right by IAM, the environment construction is completed. Therefore, one can use Athena with basic knowledge of AWS and SQL commands.
Also, since the dedicated Athena JDBC environment is distributed in the environment for executing the SQL instruction, it is possible to select any OS, SQL execution tool such as SQL Workbench / J, ETL tool like Talend, Java programming etc. It is possible to manipulate Athena with. However, it is not necessary to acquire new skills never, and most things can be operated with the feeling of using an ordinary database.
When you log in to Amazon Athena, there is a table called elb_logs as sample data. This data seems to be in S3. The queries on this table provide result in few seconds. One can check the past executed queries. You can also check the status and the time spent on the query.
Why Amazon Athena?
1.) Athena helps you analyze unstructured, semi-structured, and structured data stored in Amazon S3. Examples include JSON, CSV or columnar data formats such as Apache ORC and Apache Parquet. You can use Athena to run ad-hoc queries using ANSI SQL without having to aggregate or load the data into Athena.
2.) Athena integrates with the AWS glue data directory, which provides persistent metadata storage for data in Amazon S3.
3.) Athena integrates with Amazon QuickSight for easy data visualization.
4.) Athena generates reports or queries data using business intelligence tools or SQL clients that connect to JDBC or ODBC drivers.
5.) Create named queries using AWS CloudFormation and run them in Athena.
Table Definition & Query Execution
In order to execute queries using Athena, it is necessary to set table and column definitions in advance. One can set the table definition either in the Catalog Manager on the administration screen or by executing the SQL Create External Table statement.
The corresponding file format is as follows.
- Apache WebLogs
- CSV
- TSV
- TEXT (Custom Delimiter)
- Parquet
- ORC
- JSON
Full Serverless Managed
Athena’s feature is fully managed at all costs. Until now AWS’s big data processing service was EMR, Redshift etc, but since it is the instance-owned type, the labor and cost of operation have never been low. At Amazon Athena, you will be charged on a per-query basis, so you can execute the query at any time and pay only for the amount you used. Inside of Athena Presto is used and queries formats and so on are mostly in Presto, so users presto using EMR are likely to be able to move to Athena relatively easily.
Conclusion
Although it is an AWS that surpasses the serverless architecture such as API Gateway and Lambda, in machine learning and big data processing, It is felt that Google, which has the overwhelming ability of BigQuery processing power, seems to be somewhat lacking.